web scrapping dengan find all #1
HALO SEMUA .Hari ini ita akan belajar web scraping dengan find_all(mengambil semua data).

ini adalah code dan hasilnya

Penjelasan Alur
program
Prasarat .
Disini kita
akan menggunkan library beautifulsoup dan requests untuk mengambil data
from bs4 import BeautifulSoup
import requests
Input
Pada tahap
ini kita akan mengambil data pada url https://quotes.toscrape.com
dari page 1 Kemudian definiskan variabel html
yang mengambil requests dari url
html = requests.get('https://quotes.toscrape.com')
proses
pada tahap
ini kita instasikan beautifulsoup untuk
mengambil conten dari web target
-
kita mulai untuk mengambil datanya , pada variabel quotes ,cari semua(find_all)
elemen div dengan class quote

-kita
lakukan perulangan q pada variabel quotes yang isinya ,yaitu dengan menggunakan
variabel quote cari(find)element span dengan kelas atribut text dan
juga buat variabel author cari element
small dengan kelas atribut author
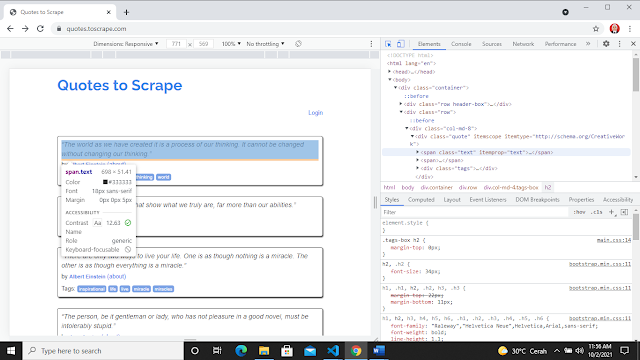

output .
lalu akan
ditampilkan seluruh quote dan author seluruh quote dan author pada page 1
print(quote)
print(author)


Komentar
Posting Komentar